[핵심 요약] — 대형주 샘플 데이터로 파이프라인 출력을 검증했다. 기술지표 계산(이평선·RSI·볼린저밴드)은 공식 API 기반으로 신뢰할 수 있지만, AI 확신도와 최종 판단은 사례 축적이 더 필요하다.
본 포스팅은 자체 개발한 퀀트 분석 파이프라인의 출력 유효성을 대형주 샘플 데이터로 검증하고, 오판 사례 및 개선 방향을 분석한 엔지니어링 검증 문서입니다.
⚠️ 이 글은 직접 개발한 퀀트 분석 시스템의 출력 결과를 검증 목적으로 기록한 내용입니다. 투자 권유나 종목 추천이 아니며, 투자 판단의 책임은 전적으로 본인에게 있습니다.
1편과 2편에서 AI 주식 리포트 시스템을 만들면서 겪었던 과정을 정리했습니다. 시스템이 어느 정도 안정됐다고 생각했지만, 사실 그것만으로는 부족합니다. 실제 종목에 적용해서 출력 결과가 의미 있는지, 믿을 수 있는 부분은 어디까지인지 검증이 필요했습니다.
가장 먼저 테스트 대상으로 고른 종목은 SK하이닉스(000660)였습니다. HBM 수요 이슈로 시장에서 가장 많이 언급되는 종목이고, 외국인·기관 수급 데이터가 풍부해서 시스템 검증에 적합하다고 판단했습니다.
데이터 수집 파이프라인 구조
검증에 사용된 데이터는 모두 KIS(한국투자증권) 오픈트레이딩 API를 통해 수집했습니다. Python requests 라이브러리로 REST API를 호출하고, 응답 JSON을 파싱해 SQLite 로컬 DB에 저장하는 구조입니다.
# KIS API 호출 및 필드 파싱
response = requests.get(
"https://openapi.koreainvestment.com:9443/uapi/domestic-stock/v1/quotations/inquire-price",
headers={"authorization": f"Bearer {access_token}", "tr_id": "FHKST01010100"},
params={"fid_input_iscd": "000660"}
)
output = response.json()["output"]초당 15건이라는 Rate Limit 내에서 대량 종목을 처리하기 위해 호출 간격을 time.sleep(0.07)로 제어하고, 주말에 일부 필드가 None으로 반환되는 특성은 data.get('field') or default 패턴으로 방어 처리했습니다. 수집된 원시 데이터는 이상값 검증 단계를 거친 뒤 판단 엔진에 넘어갑니다. 전체 파이프라인은 Synology DS423+ NAS 위 Docker 컨테이너에서 cron으로 평일 오전 8시에 자동 실행됩니다.
시스템이 뱉어낸 결과
5월 18일 기준으로 시스템이 출력한 핵심 수치입니다.
| 항목 | 결과 |
|---|---|
| 신호 강도 | 2.3점 / 6.0점 |
| 스크리닝 점수 | 7.8 / 10점 |
| 알고리즘 확신도 | 74% |
| 시스템 출력값 | 조건부 진입(Class B) |
| 1차 시뮬레이션 밴드 | 약 180만원대 |
| 2차 시뮬레이션 밴드 | 약 172~175만원대 |
위 수치는 시스템이 자동 산출한 출력값입니다. 실제 투자 기준으로 사용해서는 안 되며, 시스템 동작 검증 목적으로만 기록합니다.
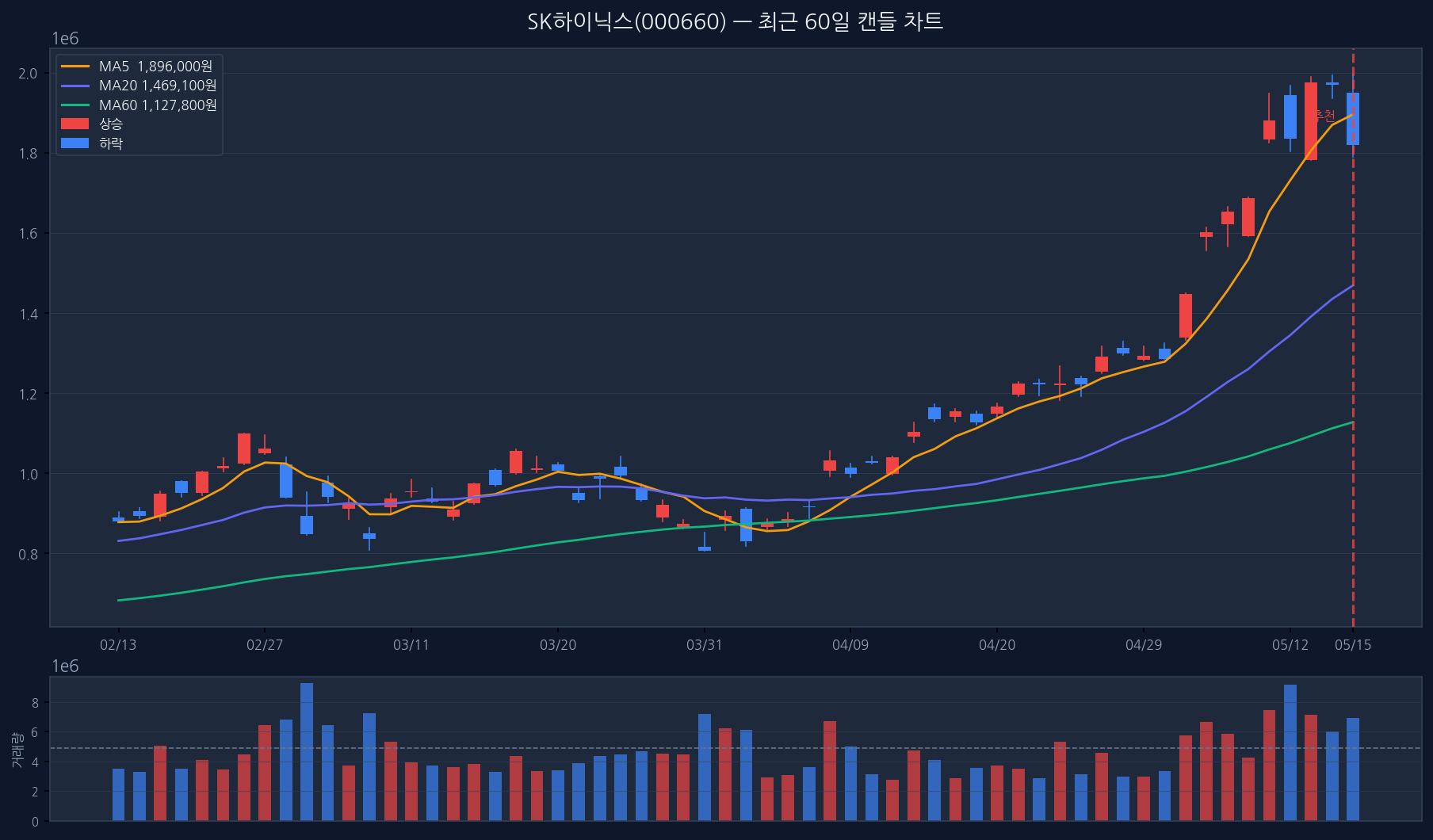
믿을 수 있는 부분 — 기술적 지표 계산
기술적 지표 수치는 KIS(한국투자증권) 공식 API에서 가져온 실제 데이터를 바탕으로 계산합니다. 이 부분은 시스템이 잘 작동하고 있다고 봅니다.
이동평균선: MA5(약 189만원)가 MA20(약 147만원) 위에서 정배열 상태. 두 선의 간격이 약 29%로 벌어져 있어 단기 과열 가능성이 있는 구간입니다.
RSI: 78.8로 과매수 구간. 추세가 꺾인 건 아니지만 숨고르기 가능성을 염두에 둬야 합니다.
거래량: 당일 거래량이 20일 평균의 1.4배. 관심이 몰리고 있다는 신호입니다.
볼린저밴드: 52주 신고가(약 197만원)까지 약 8.6% 상방이 열려 있습니다.
이런 수치 계산 자체는 데이터 소스가 공식 API인 만큼 결과를 신뢰할 수 있습니다. 시스템이 의도한 대로 작동한다는 것을 확인했습니다.
검토가 필요한 부분 — AI 종합 판단
수급 분석 수치도 마찬가지로 공식 데이터 기반입니다.
- 외국인: 5거래일 연속 순매수, 5일 누적 +28만주
- 기관: 5일 누적 +9.5만주
- 공매도 비율: 1.20%로 낮은 수준
수급 데이터 집계 자체는 잘 되고 있습니다. 다만 이 수치를 바탕으로 시스템이 내리는 최종 판단값과 알고리즘 확신도는 별도로 검증이 필요합니다.
AI가 과거 패턴을 학습해서 확률을 산출하는 방식인데, 실제로 이 수치가 얼마나 정확한지는 더 많은 사례를 쌓아봐야 알 수 있습니다. 현재로서는 참고 지표 정도로 보는 것이 적절합니다.
개발자 관점에서 본 1차 검증 결론
이번 테스트에서 확인한 것들입니다:
잘 작동하는 것: 기술적 지표 계산(이평선, RSI, 볼린저밴드, 거래량), 수급 데이터 집계, 공매도 비율 추적. 공식 API 전환 후 데이터 품질이 확실히 안정됐습니다.
더 쌓아봐야 하는 것: AI 확신도의 실제 적중률. 지금은 시스템이 “74% 확률로 유효한 신호”라고 하는데, 실제로 이후 주가 흐름과 얼마나 일치하는지는 사례가 더 필요합니다.
개선이 필요한 것: 뉴스 센티먼트 분석의 정확도. 개별 뉴스의 주가 영향도를 AI가 판단하는 부분은 아직 오판 사례가 간간이 나옵니다.
시스템을 만든다고 끝이 아니고, 실전에서 계속 검증하면서 다듬어야 한다는 걸 이번 테스트를 통해 다시 확인했습니다.